English proposal
This is the translated version of the original, German proposal. Excerpts from the original proposal can be found here.
Summary
The view of IT-security has traditionally been dominated by the borders between a supposedly trustworthy inner world and a potentially hostile outer world. Consequently, many classical security mechanisms focus on securing these borders, and trust in artefacts is established mainly based on their identity and origin. However, the borders between the "inner" and the "outer" world are blurred by aspects like networking, mobility and dynamic extensibility. Hence, a more sophisticated view of security is needed. In IT-systems, tasks are increasingly dealt with by means of flexible and dynamic compositions of multiple services that communicate in a physically distributed system. This causes a complexity that hinders the conceptual understanding of security aspects as well as the reliable verification of security guarantees on a technical level.
The priority programme "Reliably Secure Software Systems", thus, aims at a new conceptual and technical framework for IT-security. The goal is to support the certification of security guarantees based on well-founded semantics of programs and of security aspects. The first guiding theme is the development of precisely defined (and, thus, verifiable) security properties. This shall enable a perspective on security that, on the one hand, abstracts from technical details of implementations and, on the other hand, permits one to model the manifold security requirements and guarantees in an adequate and precise way. The second guiding theme is the development of analysis methods and tools that target the reliable verification of security properties of systems. This will create the basis for a semantically substantiated (and, thus, reliable) certification of security guarantees for computer programs. The third guiding theme is the development of concepts for understanding and certifying security aspects even in complex software systems (hence, for security in-the-large). This requires the adaptation of established techniques for abstraction, decomposition and step-wise refinement to the field of security, which involves conceptual as well as technical problems. For instance, it shall become possible to derive abstract security guarantees, as they are typically required on the level of business processes (e.g., "need-to-know" or "separation-of-duty"), from the low-level properties that are guaranteed by security mechanisms.
Within the priority programme, information flow control plays a key role: information flow properties abstract from technical implementation details; information flow analyses can take into account all aspects of a program's logic; compositionality results for information flow properties enable a well-founded, modular view on complex systems. This approach provides the essential features for a semantically substantiated certification of security aspects for complex software systems. The development of further, equally well-suited approaches to system-wide security is desirable. With respect to declarativeness and semantic foundations, existing information flow properties shall serve as a role model for new security properties.
The priority programme aims at initiating a paradigm shift in software-security research based on recent advances in information flow control, in program analysis and in verification. The programme shall un-leash the vast potential for synergies between these three disciplines by facilitating interdisciplinary cooperations.
Focus and Vision of the Priority Programme
The security of software systems plays a decisive role in our society. Information has become an asset that can be processed electronically, although being marketed and traded just like physical goods. The nondisclosure of personal data is essential for protecting privacy. In electronic voting, for instance, nondisclosure is necessary – in addition to the integrity of individual ballots and of results of polls – for protecting democracy. The desire for secure data processing is demonstrated by the turnaround of security software, which is estimated to exceed 10 billion US dollars in 2008 [11]). Nevertheless, Computer Science is apparently still far from an acceptable solution to the problem of security, as the enormous amount of attacks and vulnerabilities shows (compare, e.g., [51]).
Need for a Paradigm Shift
In contrast to other areas of Computer Science, IT-security is lacking adequate quality criteria and reliable quality tests for complex software systems on a technical level. Instead of establishing guarantees for the secure operation of programs, certification of security-critical systems focuses on (and limits itself to) methodical aspects of software development (for instance in the context of the Common Criteria [6]). Although this may positively influence the security of the developed software, it does not result in reliable security guarantees on a technical level. Furthermore, the concretization of security requirements in the form of properties (which is standard for functional or fault tolerance requirements) is often skipped during the development of security-critical software. Instead, software developers often directly jump to realization details like the chosen security mechanisms, although a concise specification of security requirements forms an indispensable reference point for a reliable security analysis.
The absence of reliable security guarantees is, in practice, concealed by the intense use of trust models. Often, security-relevant decisions are solely based on the identity, integrity, and origin of programs. For instance, cryptographic certificates only guarantee that a given program code has not been modified after being released by the code producer. They communicate neither the quality nor the extent of the security checks performed before the release. Hence, they do not offer a semantically substantiated basis for security-relevant decisions and certainly do not justify universal trust in the digitally signed programs. One should also note that the user-specific security requirements are usually not even known to software producers when they perform their security checks. Moreover, user-specific security requirements may be in conflict with a producer's interests. The recent transmissions of personal data by popular Internet browsers is only one example for this (e.g., [15, 16]).
Classical security technology is dominated by a strong focus on security mechanisms. Mechanisms like authentication components, cryptographic protocols, network filters, virus scanners and access controls, for instance, have proven themselves in many respects. These mechanisms are primarily employed for creating a zone that is protected from intrusions of unknown, potentially malicious programs. The predominant paradigm of a trust-based access control, which assesses programs based on their origin, can be illustrated by the metaphor of a medieval castle: Its inner courtyard is separated from its environment by unsurmountable walls and can only be entered through few gates. The gates are well guarded in order to restrict entry to persons known as trustworthy. While this metaphor may be plausible for simple systems (i.e., for security in-the-small), it is not appropriate for grasping security problems in complex systems. On the one hand, open networks and extensible software offer a large number of access points, such that in addition to guarding each individual "gate" the interplay between these guards needs to be coordinated as well. On the other hand, programs may be able to perform security-relevant actions and interactions that need to be controlled even after the program permittedly entered a given system. Moreover, access controls usually confront users with a plethora of detailed decisions, as for instance «Click "continue" if you want to execute setup.exe!» or «Allow LAN access to application "browser"?». Such questions suggest a simplicity of security-relevant decisions. However, they do not even provide sufficient information for making decisions in an informed way. In particular, it remains unclear what the consequences of affirmative answers are with respect to security in-the-large. For instance, to what extent could the confidentiality of personal data be jeopardized in the two example decisions above?
Significant improvements of security mechanisms have been achieved. However, the last decade also showed that a too strong focus on security mechanisms, as it is customary today, is not suitable for mastering the complexity of security of modern software systems, and, hence, for reliably obtaining security in-the-large. Though well-established, this paradigm of IT-security has obviously reached its limits. To achieve security in-the-large, concepts are needed that allow one to abstract from technical details like the specific security mechanisms employed in a system in a semantically sound way. To conquer the conceptual complexity of security in-the-large, it would be desirable to adapt common approaches for reducing complexity from other areas, including techniques for abstraction, decomposition and step-wise refinement. However, this is not straightforward due to fundamental problems (like, e.g., the refinement paradox [29]).
The Approach of the Priority Programme
The priority programme aims at surmounting the conceptional limits of classical security technologies. It shall contribute to the urgently needed paradigm shift in IT-security from the current trust-based and mechanism-centric view to a property-oriented and semantically substantiated view. In order to enable the reliable certification of security guarantees, new techniques and tools will be developed particularly following three main guiding themes:
-
A property-oriented approach to IT-security. Substantiating security aspects by means of precisely defined properties will enable a different perspective on the manifold security requirements than it is common today. It shall form the basis for the analysis of security requirements (e.g., for identifying contradicting requirements) and for proofs of security guarantees on a technical level. While suchlike approaches are common in other areas of Computer Science, the breakthrough in the area of IT-security is yet missing. This is surprising, as precisely defined security properties that seem suitable for serving as a basis for a property-oriented approach are known for decades. Particularly promising is the family of so-called information-flow properties, characterizing security aspects by certain restrictions to the information flow during a program's run-time. This approach allows for expressing both confidentiality as well as integrity requirements and, hence, offers a unified view on different security aspects. Information flow properties even fit to the requirements of the other two guiding themes which are described below. Before these property-oriented approaches can be realized, several fundamental questions have to be clarified and answered. Central research goals in this direction are
- adapting established security properties like noninterference [12] to practical demands,
- practically evaluating these properties, and
- developing new security properties that have a precise formal definition and are practicable.
-
Semantically substantiated security analysis. Respecting program semantics in a substantiated fashion will render security analyses possible on a technical level. The consideration of single actions (as the access operations of a program) alone is often not sufficient since full program executions have to be analyzed. For some security aspects it is even necessary to compare multiple possible program executions or even consider the set of all possible executions as a whole. This distinguishes security from other requirements such as functional correctness or safety.
Possible approaches for substantiated security analyses could be, for example, the explicit consideration of program semantics in a formal verification, its implicit consideration by using program logics, and focusing on relevant semantic aspects of a given security property by using a specialized security type system. Independent of the chosen approach, the semantics of the respective programming language has to be accounted for carefully, the analysis may only draw logically valid conclusions, and the correctness of the used analysis tools must be ensured at the implementation level. Following a successful analysis, the established security guarantees can be formulated in the form of certificates which, in contrast to cryptographic certificates, are semantically substantiated. Semantic certificates can then even serve as a basis for liability agreements between software producers and users. If the proof-carrying code principle [38] is utilized, users could even be offered the possibility of verifying the correctness of the security analysis on a computer of their choice. Central research goals in this direction are
- advancing semantically substantiated security analyses in order to significantly improve their yet limited efficiency and precision,
- developing reliable tools for automating security analyses,
- creating infrastructure components for a semantically substantiated certification, and
- developing approaches for repairing programs after a security analysis has failed.
-
Thinking tools for security in-the-large. The adaptation of techniques for abstraction and modularization to the area of security will allow for a reliable certification of security guarantees even for complex software systems (hence, for security in-the-large). The specification of security guarantees as properties defined in terms of interfaces between system components (as it is possible, e.g., with information flow properties) offers an abstraction from technical details of implementations within components. With the help of compositionality results, the security guarantees for single components can be used for deducing security guarantees for complex, composed software systems. In order to manage the complexity of modern software systems, the combination of abstraction and modularization is useful. It will, for instance, make it possible to firstly derive guarantees for more complex services from guarantees for security mechanisms and to finally deduce the desired security guarantees for full business processes. A substantiated security analysis requires dealing with the conceptional differences between security properties. This particularly includes the transition from rather technique-oriented security guarantees (as they are common for mechanisms) to the rather abstract security guarantees for complex software systems (e.g., "need-to-know" and "separation-of-duty" on the level of business processes). The fundamental differences between security properties and traditional system properties necessitate the development of new abstraction techniques and compositionality results which each have to be substantiated by respective correctness results. Central research goals of this direction are the development of
- novel compositionality results for reducing the complexity in-the-large and deducing substantiated end-to-end guarantees,
- abstractions which make security guarantees intelligible even for complex applications,
- tool support for modular security analyses which allow for the combination of different analysis techniques, and
- approaches for step-wise software development, which by construction incorporate the adherence to security requirements.
Envisioned Results of a Focused Priority Programme
The aspired paradigm shift shall facilitate a substantiated treatment of the security problem. The security models and analyses developed within this priority programme shall enable reliable security guarantees on a technical level. They shall as well render a more flexible usage of extendable architectures possible, including a risk-free usage of software compononents coming from unknown software producers. Security in-the-large shall, on the one hand, become technically possible, and on the other hand become conceptionally understandable and communicable with the help of suitable thinking tools. The developed technologies and methods will have a substantial and enduring positive impact on the usage as well as on the administration and construction of software systems.
The ultimate vision is a fundamentally improved handling of the security problem in software systems. It shall not only finally offer an adequate level of security but enable an extensive automatization of security-relevant decisions. Semantically substantiated security certificates will form the basis for ensuring that programs adhere to all desired policies. Security policies are specified in a semantically substantiated manner which may be flexibly composed from producer-, user- and application domain-specific parts. The semantic substantiation with security properties permits security policies to serve as reference points for technical security checks of software systems as well as for the identification of contradicting requirements. Declaratively defined security properties will not only enable substantiated descriptions of security guarantees, but also support the subjectively understandable communication of such guarantees. This way, quality differences with respect to security become transparent to users and better marketable for software producers. Hereby an informed and responsible handling of the security problem becomes possible.
The aspired paradigm shift will, thus, induce a change regarding user interaction in the long run. The results of the priority programme will, however, also improve the currently common user interaction, as illustrated in the following:
It will be possible to better inform users about security aspects, such that they are sufficiently informed when making decisions. Cryptographic certificates at least offer a user the possibility of determining the producer of a program and verifying the integrity of program code. However, users still have to trust blindly that a program's behavior adheres to their security requirements. By means of the security models and analyses developed within this priority programme it shall finally become possible to verify conformity on a technical level and thereby to exclude, e.g., that private data is propagated by a program. For instance, a query like «Program finances.exe wants to access the Internet (destination IP: 199.2.456.0). Permit?» could optionally offer further information, as «The transmitted data will be independent of the personal data in the directories MyDocuments, MyPictures and MyMusic.», «The transmission will only include information resulting from your today's interaction with the program.», or «This transmission will potentially include information about your bank account or custody account.». This way, a user would not only be presented possible actions but also their potential consequences. Displaying the sent data (an option already available today) would not provide the same information, as it is in principle impossible to reliably conclude from the raw data all information encoded in it. This would additionally require for knowing the used interpretation or at least knowing all sources from which the data was generated. Thus, semantically substantiated information flow analyses are indispensable.
The range of possible user decisions could be reasonably supplemented by new options. For instance, before the installation of a program such as, e.g., a browser plug-in, the user could be offered to choose not only «Do you really want to install the plug-in? (Yes/No)», but additionally also «Install plug-in, but disable all features transmitting information about visited web sites.», or even «Choose all sources from which data may be passed on by the plug-in. All non-conforming features of the plug-in will be disabled.». Hence, completely new possibilities arise, which will range from the custom-tailored configuration of programs to the automatic repair of insecure programs. Adequate security properties and correct security analyses will reliably guarantee security in a way that future users may actually rely on the adherence to their security policies.
Security-relevant decisions will become reliably automatable. Instead of making decisions for every single occasion, users shall be offered the possibility to specify custom preferences in the form of semantically substantiated security policies. Based on security policies defined in advance and the choice of either optimistic or pessimistic decision strategies (depending on the user's preference), affirmations or rejections can be computed largely automatically. The reliability of the made decisions would be guaranteed by security analyses, even though user interaction would only be required in exceptional cases. Even incremental definitions of custom security policies would be conceivable. In case of an exception users could be offered to adapt their security policy, such that the particular decision as well as related ones can henceforward be made automatically.
These improvements will only become possible when ideas and technologies of different areas of Computer Science are combined. This priority programme shall establish cooperations between scientists working in the areas of IT-security, program analysis and verification, and shall provide the general conditions for these cooperations. The development of reliable security analyses has become realistic only by recent research results in these three areas (compare "State of the Art"). For example, today powerful verification tools and scalable techniques for program analyses are available which would not have been reachable or may even have been hardly imaginable only few years ago. Germany offers ideal prerequisites for this interdisciplinary research project.
State of the Art and Challenges
We discuss the state of the art and resulting challenges along with the involved core disciplines: Security, program analysis and verification.
Security
After a concise overview of traditional access control and proof-carrying code, information flow will be depicted in general and in two important instances.
Access control. Security policies describe security requirements for a system. Access controls (e.g., mandatory access control, discretionary access control or role-based access control) offer traditional protection mechanisms for confidential data: authorizations of subjects are defined with respect to single data elements and actions operating on them. Known languages for security policies (e.g., [26, 9, 41]) permit the specification of such access controls and extend them with respect to obligations or the delegation of rights. Access control operates on the containers which store the data. Information that is derived from system behavior does not belong to a controlled container and is, thus, also not protected. Traditionally, access control is implemented via reference monitors that monitor the execution of a program and suppress actions that would violate the security policy. The reference monitor makes decisions based on the current state of the system and the respective type of access. This way, security requirements depending on more than the information that is obtainable by monitoring a system cannot be guaranteed. However, prohibiting information flows between different parts of a system would, for example, depend on the set of all possible system runs.
Proof-carrying code (PCC). Reference monitors may lead to significant performance penalties. Hence, other approaches have been developed which integrate security checks (such as, e.g., array bounds checks) into the monitored program itself using program analysis (for example using type systems) and program transformation. A program analysis determines those locations within a program which might violate the security policy at run-time. A program transformation then inserts suitable run-time checks at these locations in order to guarantee the desired security requirement. It depends on the potential of the analysis technique which requirements can already be guaranteed statically. In order to verify security guarantees directly and without expensive analyses, the principle of proof-carrying code [38] has been developed. Here, programs are supplemented with automatically verifiable proofs for whether they satisfy the security requirements [49]. These proofs (also called certificates) are generated by certifying compilers or, in extreme cases, proved interactively. PCC becomes relevant whenever a full analysis is too expensive (as, e.g., on smart cards), or whenever the security-critical core of a system shall be minimized. This is because a certificate verifier is often simpler than an analysis tool by orders of magnitude and can, hence, itself be verified more easily. One challenge of this priority programme is to transfer this principle to information flow properties.
Information flow control (IFC). IFC serves controlling the information flow and data flow within a system. In this context, information for example corresponds to values of variables or recently executed actions. Information can be leaked to the outside explicitly by copying data as well as implicitly by combining statical knowledge about the system with observations of the dynamic system behavior. IFC allows the modeling of integrity (by controlling the impact of information on the results of computations) as well as confidentiality (by restricting future information flow to a limited number of paths). Noninterference constitutes a central criterion for the realization of IFC. It demands that secret data or actions must not have any influence on the publicly visible system behavior. In consequence, an attacker then cannot draw any conclusions about secrets based on her observations. The power of an attacker depends on the extent to which she is able to distinguish different system states. By combining those system states to classes, which are indistinguishable to an attacker, one obtains an equivalence relation characterizing the observable system behavior. A secure (deterministic) system therefore has to run through identical classes of system states independent of varying confidential inputs. Particularly, a system is secure (with respect to noninterference) if it behaves deterministically for an observer [44].
Language-based IFC. Language-based approaches study information flow at the level of programs. If input and output of a program is separated into visible and confidential parts, then a program is said to be secure if it generates the same visible output for every two inputs with identical visible parts. Hence an attacker cannot conclude information about the confidential part from visible outputs. The development of security type systems for information flow analyses is a very active research topic. It started with a basic calculus [54] for a simple imperative language comprising assignments, loops and conditions. The subsequent progress happened along different, orthogonal directions: the extension of the domain to further programming concepts, the extension of observer abilities, and modeling security with respect to requirements weaker than noninterference.
At the end of the 90s, extensions and translations of the basic calculus were made towards procedures [52], exceptions [37] and the treatment of functional [43] and, in particular, object-oriented programs [37, 3]. For multi-threaded programs, the behavior of the scheduler is security-critical. This led to research that imposes requirements on the behavior of schedulers and, respectively, thread synchronization [45]. For mastering communication in the context of multi-threading, several type-based approaches have been developed [31]. Even though most language concepts are covered by type systems, the challenge remains to combine them to suitable type systems for real programming languages. The complexity of the resulting type calculi grows with the richness of the programming language and makes the automatic verification of these calculi indispensable. New programming paradigms as, for instance, dynamic service planning and composition require for the development of novel techniques. These techniques could, e.g., take into account the influence of confidential information to the planning of services.
Adequately modeling capabilities of attackers is decisive for excluding covert channels contained in a system of interest. For this reason, type systems have been extended to consider timing aspects [53, 46], and program transformations have been developed for eliminating security-relevant run-time differences [22]. However, this by far does not capture all possibilities of covert channels. Further examples are the energy or resource consumption of a system. Several techniques have been proposed for avoiding information flow by analyzing statistical distributions of system runs [35, 47]. The limits of noninterference are reached if publicly accessible information intentionally depends on public data. This is the case, for example, whenever previously secret information is made public, whenever passwords are checked, or whenever secret data is transmitted through public communication channels in an encrypted form. In order to solve these problems, several mechanisms have been developed. Quantitative IFC [27, 33] does not completely prohibit the information flow but limits it to an initially determined number of bits. In contrast, declassification mechanisms permit the explicit declassification of confidential information [48]. Other approaches replace noninterference with complexity-theoretic approximations [23]. Integrating suchlike approaches with multi-threading is yet completely unsolved.
Specification-based IFC. Language-based approaches base on the level of implementations and are, thus, not suited for modeling security on abstract design levels. Specification-based approaches use automata (or also process algebras) and their runs (traces) for their system models. Different security levels are represented by domains and each transition is assigned to one such domain. A policy determines between which domains information flow is permitted. A system is then said to be secure if (a) the output of a system is consistent with a (sub-)sequence of transitions visible to an observer in a certain domain, and (b) the observer is unable to conclude non-visible transitions [12]. Her observations therefore have to be consistent with different traces. This typically results in security policies being closure properties over sets of traces which show the same behavior from the view of an observer. The question of which closure properties are adequate for security led to the development of frameworks [36, 28] allowing to adapt the notion of security to individual systems. A continuous methodology for a formal modeling of such security notions [19] or of covert channels [32] is yet missing. On a large scale, the verification of whether a system satisfies a policy is performed using compositionality results [30]. On a small scale, typically inductive proofs are used for this purpose. However, suitable development methodologies for efficient, deduction-based analyses are missing here, too.
In order to come from the design level to a correct implementation, formal software engineering stipulates step-wise refinement. In this process, every refinement step shall preserve the desired security properties. Unfortunately, most known refinement mechanisms do not preserve security properties. The challenge in this context is being able to apply the principle of step-wise refinement also for security-critical applications. First conceptional approaches exist in the area of process algebras and automata for refinement in the sense of reducing indeterminism or refinement of actions and data types. However, solutions for transferring such concepts to realistic applications are yet missing.
Program Analysis
Program analysis was initially developed in order to perform code optimizations in compilers. First intra-procedural analyses and optimizations originate in the 60s; in the 70s not only a variety of increasingly precise analyses were developed, but also theoretical foundations like monotonous data flow frameworks [20] and abstract interpretation [7]. Since the 80s, a plethora of new techniques exists, which in particular allow for precise inter-procedural analyses. Empirical studies show that inter-procedural constant propagation [5] is significantly more effective than a purely intra-procedural one. The static single assignment form [8] was developed to provide a multi-purpose standard analysis.
At the same time, the trade-off between precision and cost was being considered from an engineering perspective: for many analysis problems there exist precise but expensive algorithms but also fast and imprecise ones; the choice of an engineer depends on the respective application and her scalability requirements. The decisive categories in this context are flow sensitivity (flow-insensitive techniques do not consider the ordering of instructions), context sensitivity (the calling context of procedures is taken into account – very expensive) and object sensitivity (attributes are distinguished based on the object they belong to – even more expensive).
Points-to analysis shall serve as an example. The analysis of realistic Java programs is impossible or useless without a precise points-to analysis. Good algorithms have been sought for for many years, since at the beginning even flow-insensitive analyses were only applicable to small programs. A breakthrough did not succeed until the year 2000 (compare, e.g., [25]). Many applications – including the objective of IFC – however still use rather insufficient points-to analyses.
Based on inter-procedural analyses, points-to analysis and other techniques, program dependency graphs [18] have become a standard data-structure since the 90s. They allow for extensive analyses, particularly including program slicing and dependency analyses. The latter are flow-sensitive by construction, but context- and object-sensitive slicers for full Java were not available until 2004 [14]. Today, commercial slicing implementations for C and C++ exist. Later, the still fragile precision was improved with the help of path conditions [50], which for the first time utilized dependency graphs for IFC.
The potential of modern program analyses is recognized little by little outside of a small community. One example for their industrial application is the prediction of the caching behavior of Airbus software with the help of abstract interpretation [56]. The potential of program analyses for IFC is however not yet exhausted, as today's IFC technologies are mostly not flow, context of object-sensitive, or do not scale to real languages; integrating modern analysis algorithms will reduce false alarms and make real systems tractable. Nevertheless, language-based IFC will face several challenges in the future, even though it fully exhausts the potential of today's type systems or program analyses:
- Precision/scalability: Current analysis techniques are insufficient for really large systems. The example of points-to analysis however shows that algorithmic breakthroughs can be anticipated to result from intense effort. Recently, path-sensitive analyses, which for a program location take into account how this location could be reached, have been proposed. This additionally leads to an increased precision and has a high potential for security analyses; scaling, path-sensitive IFC however is a technical challenge.
- Compositionality/modularity: Current techniques always analyze a whole system; in a world of mobile software components and dynamically configurable systems it however has to be possible to analyze isolated components without a loss in precision, in order to afterwards combine the intermediate results. Security type systems do have this property, but for flow-sensitive techniques (not to mention context-, object- or path-sensitive ones) this is yet an open problem.
- Symbolic analyses/use of solvers: All classical analyses are based on abstract values representing types or data-flow information. If one would instead compute with symbolic expressions, then one would obtain completely new possibilities for the precision as well as for the semantic characterization of IFC situations. Even today one can extract systems of equations or path conditions from programs, whose solutions provide precise constraints (so-called witnesses) for flows. In order to apply this on a large scale it is necessary to utilize computer algebras or the new generation of solvers (e.g., SAT solvers); the scalability is completely open.
Verification
Automatically proving mathematical theorems was a dream originating from the initial stages of AI that was sustained until the 80s but never led to substantial success. Only the consequent inclusion of humans into the verification process led to a breakthrough in the form of interactive theorem provers [4, 13, 40]. Humans have to specify the coarse proof structure and the machine then checks it for logical correctness and tries to supplement single proof steps automatically. In the beginning, this was extremely time-consuming for the human user. However, after 20 years of research, two initial barriers have now been mitigated: Firstly, there now exist large libraries of mathematical fundamentals, for instance in the Mizar system or HOL Light. Secondly, interactive theorem provers now provide for powerful verification procedures (decision or only semi-decision techniques) for many important theories from propositional logics to real closed fields [34]. Therefore it is now possible to (partially) verify controversial mathematical proofs such as the one for the four color theorem or the one for the Kepler conjecture [39].
The primary application of theorem provers in Computer Science however is software modeling and software verification. For about five years significant applications on a previously unthinkable scale exist: programming languages, compilers and cores of operating systems have been formalized and verified [21, 24, 17, 1]. We want to use exactly this potential for verifying tools for security analyses and methods themselves. This is indispensable for guaranteeing the reliability of the tools because of the complexity of real programming languages as well as of program analyses and type systems. First steps in this direction are the work on the verification of traditional program analysis algorithms [42, 55]. The challenge now on the one hand consists of combining the manifold approaches for semantics, types and program analyses into a comprehensive, sufficiently universal and abstract theory. On the other hand, it especially consists of providing these theories in a theorem prover for verifying things like type systems and analysis algorithms for IFC. Not only the abstract mathematical level constitutes a major challenge, but also the correctness of programs automatically or manually generated from them. This is due to the fact that the automatic generation of efficient code from abstract functional specifications still requires for domain-specific techniques. In the area of program analysis, no sustainable approaches exist at the moment.
Besides the turn towards automatic theorem provers, the last decade showed another progress that significantly promoted software verification: The concentration on proofs for simple properties of source programs with the help of automatic provers [10], called SMT solvers [2]. These solvers rely on a combination of propositional logics (based on extremely efficient SAT solvers that are even able to quickly solve formulas comprising 106 variables), linear arithmetics, special theories like bit vectors, and heuristics for instantiating quantifiers. We envision a twofold potential for their application: The automatic verification of information flow properties of programs (instead of traditional safety properties) and the use of SMT solvers for the interactive verification of analysis tools. A long-term challenge in this area is to develop particular decision procedures for first-order formulas which go beyond eliminating quantifiers for purely arithmetic formulas.
Work Plan
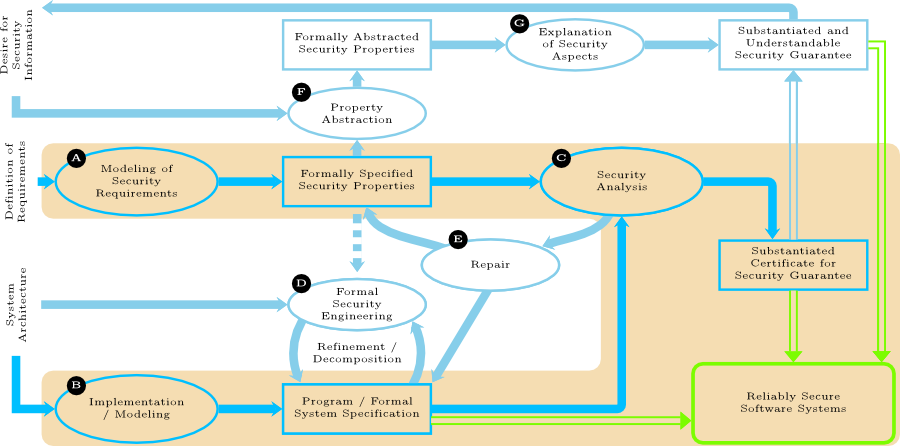
The work of the priority programme will be geared to the three guiding themes (see The Approach of the Priority Programme). While the first two guiding themes will be tackled in their own working areas (namely A and C), the third guiding theme has a rather cross-cutting character. The above figure sketches the data flow between the different working areas of the priority programme (depicted as ovals).
The region highlighted in orange color represents the working areas which are indispensable for the aspired goal of a semantically substantiated certification of reliably secure software systems. The working area Modeling of Security Requirements (A) will provide techniques for requirement analyses, a catalog of security properties (particularly practicable variants of noninterference) and, based on these properties, illustrating examples of specifications of security requirements (including substantiated justifications for their adequacy). Within the working area Security Analyses (C), novel analysis techniques and tools will be developed and proofs for guaranteeing their correctness will be established. In order to understand software systems on different levels, ranging from abstract specifications to program code, working area (B) will provide techniques for modeling security-critical systems and formal characterizations of program semantics. The certificates resulting from a security analysis will ultimately offer the aspired reliable security guarantees due to their semantic substantiation.
The remaining, non-highlighted working areas of the figure are concerned with questions which are not necessary for semantically substantiated certification of security from a theoretical perspective, but are indispensable for the practical realization of the vision of the priority programme. Working areas (D) and (E) deal with questions of software engineering, particularly the step-wise development of certifiably secure software and the repair of insecure programs based on information resulting from failed security analyses. Working areas (F) and (G) together aim for a subjectively understandable but substantiated communication of the certified security guarantees.
Exemplary Research Projects and Research Questions
The following list of possible research projects depicts how the different working areas of the priority programme can be instantiated with concrete research questions. The parenthesized letters respectively refer to the affected working areas.:
-
Abstractions for information flow control (ACEFG). Abstractions providing a simplified view on complex software systems will be sought. They shall simplify, for instance, the security analysis or the repair of insecure programs. It shall be investigated to what extent abstractions can be generated which are targeted on making semantically substantiated security guarantees subjectively more understandable.
-
Automatic generation of code for information flow control algorithms (C). Techniques will be developed, which automatically generate implementations from functional descriptions of information flow analyses. They shall be both efficient and correct by construction. It shall be analyzed how mutable data structures as, e.g., arrays can be utilized.
-
Information-theoretic analysis of covert channels (AB). Unwanted flow of information is particularly made possible by covert channels within the run-time environment of programs. For typical such environments (like, for example, browsers, virtualization software or operating systems) formal security models will be developed, which allow for a qualitative and quantitative evaluation of the threat induced by covert channels.
-
Precise information flow control for mobile software components (C). Precise and compositional analysis methods for information flow control in distributed and mobile software components will be developed and formally verified. Furthermore, the developed methods shall be implemented and empirically checked with respect to their scalability.
-
Requirements engineering for information flow security (AD). The results of forensic analyses will be used for identifying insecure information flows and, based on these results, desired information flow properties. Subsequently, these properties will be defined precisely and partially even formally, in order to serve as a reference point for the development of new, improved systems.
-
Reliably secure service-oriented architectures (ABD). Based on an existing application scenario in the area of crisis control panels, property-oriented modelings of security requirements for services will be developed. It will furthermore be investigated how these requirements can be decomposed into security requirements for auxiliary services.
Priority-Programme-Wide Application Scenarios and Case Studies
Synergies between single projects will result from relations between research topics, the competition between analysis tools and modeling techniques, and also from intense communication and interdisciplinary cooperation within the priority programme. Furthermore, three joint case studies will facilitate the cooperation between universities. These case studies will be chosen and refined based on the orientation of the approved projects at the beginning of the priority programme. In addition to the cooperation, they shall also promote the interoperability and continuity of the developed methods and tools. They could, for instance, stem from the following areas of application: Internet browser (security of extendable software systems), e-health and telematics (compliance, security of distributed systems), e-voting and voting machines (security of mobile and embedded systems), e-business applications (security of service-oriented architectures).
The results of the case studies conducted within the priority programme will not only serve the evaluation of the developed methods and tools, but will also be the source for demonstrators. The latter shall illustrate the results of the priority programme particularly to interested representatives of industrial companies and public authorities. Several companies and authorities have already expressed their interest.
References
- [1]
- E. Alkassar, N. Schirmer, and A. Starostin. Formal pervasive verification of a paging mechanism. In Tools and Algorithms for the Construction and Analysis of Systems, pages 109-123. Springer, LNCS 4963, 2008.
- [2]
- C. Barrett, L. de Moura, and A. Stump. Design and results of the 1st satisfiability modulo theories competition. Journal of Automated Reasoning, 35(4):373-390, 2005.
- [3]
- G. Barthe, T. Rezk, and A. Basu. Security types preserving compilation. Comp. Languages, Systems and Structures, 33(2):35-59, 2007.
- [4]
- Y. Bertot and P. Castéran. Interactive theorem proving and program development: Coq'Art: the calculus of inductive constructions. Springer, 2004.
- [5]
- D. Callahan et al. Interprocedural constant propagation. In ACM Symp. on Compiler Construction, pages 152-161. ACM, 1986.
- [6]
- Common Criteria for information technology security evaluation. http://www.commoncriteriaportal.org/, 9/2006.
- [7]
- P. Cousot and R. Cousot. Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints. In ACM Symp. on Principles of Programming Languages, pages 238-252, 1977.
- [8]
- R. Cytron et al. Efficiently computing static single assignment form and the control dependence graph. ACM Trans. Program. Lang. Syst., 13(4):451-490, 1991.
- [9]
- N. Damianou et al. The Ponder policy specification language. In Int. Works. on Policies for Distributed Systems and Networks, pages 18-38. Springer, LNCS 1995, 2001.
- [10]
- C. Flanagan et al. Extended static checking for Java. In PLDI, pages 234-245, 2002.
- [11]
- Gartner Inc. Gartner predicts worldwide security software revenue to grow 11 percent in 2008. Pressemeldung http://www.gartner.com/it/page.jsp?id=653407, 22. April 2008.
- [12]
- J. A. Goguen and J. Meseguer. Security policies and security models. In IEEE Symp. on Security and Privacy, pages 11-20, 1982.
- [13]
- M. Gordon and T. Melham, editors. Introduction to HOL: a theorem-proving environment for higher order logic. Cambridge University Pess, 1993.
- [14]
- C. Hammer and G. Snelting. An improved slicer for Java. In ACM Works. on Program Analysis for Software Tools and Engineering, pages 17-22. ACM Press, 2004.
- [15]
- Heise Online. Angreifer können Liste besuchter Webseiten auslesen. Meldung im Newsticker http://www.heise.de/newsticker/meldung/86113, 02. März 2008.
- [16]
- Heise Online. Chrome ruft Google. Meldung im Newsticker http://www.heise.de/newsticker/meldung/115537, 05. September 2008.
- [17]
- G. Heiser et al. Towards trustworthy computing systems: taking microkernels to the next level. Operating Systems Review, 41(4):3-11, 2007.
- [18]
- S. Horwitz, T. Reps, and D. Binkley. Interprocedural slicing using dependence graphs. ACM Trans. Program. Lang. Syst., 12(1):26-60, 1990.
- [19]
- D. Hutter, H. Mantel, I. Schäfer, and A. Schairer. Security of multi-agent systems: A case study on comparison shopping. Journal of Applied Logic. Special Issue on Logic Based Agent Verification, 5(2): 303-332, 2007.
- [20]
- J. Kam and J. Ullman. Monotone data flow analysis frameworks. Acta Informatica, 7(3):305-317, 1977.
- [21]
- G. Klein and T. Nipkow. A machine-checked model for a Java-like language, virtual machine and compiler. ACM Trans. on Programming Languages and Systems, 28(4):619-695, 2006.
- [22]
- B. Köpf and H. Mantel. Transformational typing and unification for automatically correcting insecure programs. Int. Journal of Information Security, 6(2/3):107-131, 2007.
- [23]
- P. Laud. Semantics and program analysis of computationally secure information flow. In European Symp. on Programming, pages 77-91. Springer, LNCS 2028, 2001.
- [24]
- X. Leroy. Formal certification of a compiler back-end or: programming a compiler with a proof assistant. In ACM Symp. on Principles of Programming Languages, pages 42-54, 2006.
- [25]
- O. Lhoták and L. Hendren. Evaluating the benefits of context-sensitive points-to analysis using a BDD-based implementation. ACM Trans. Softw. Eng. Methodol., 18(1):1-53, 2008.
- [26]
- T. Lodderstedt, D. Basin, and J. Doser. SecureUML: A UML-based modeling language for model-driven security. In UML 2002, pages 426-441. Springer, 2002.
- [27]
- G. Lowe. Quantifying information flow. In 15th IEEE Comp. Security Foundations Works., pages 18-31, 2002.
- [28]
- H. Mantel. Possibilistic definitions of security – an assembly kit. In IEEE Comp. Security Foundations Works., pages 185-199, 2000.
- [29]
- H. Mantel. Preserving information flow properties under refinement. In IEEE Symp. on Security and Privacy, pages 78-91, 2001.
- [30]
- H. Mantel. On the composition of secure systems. In IEEE Symp. on Security and Privacy, pages 88-104, 2002.
- [31]
- H. Mantel and A. Sabelfeld. A generic approach to the security of multi-threaded programs. In 14th IEEE Comp. Security Foundations Works., pages 126-142, 2001.
- [32]
- H. Mantel and H. Sudbrock. Comparing countermeasures against interrupt-related covert channels in an information-theoretic framework. In 20th IEEE Comp. Security Foundations Symp., pages 326-340, 2007.
- [33]
- S. McCamant and M. Ernst. Quantitative information flow as network flow capacity. In ACM Conf. on Programming Language Design and Implementation, pages 193-205, 2008.
- [34]
- S. McLaughlin and J. Harrison. A proof-producing decision procedure for real arithmetic. In Automated Deduction — CADE-20, pages 295-314. Springer, LNCS 3632, 2005.
- [35]
- J. McLean. Security models and information flow. In IEEE Symp. on Security and Privacy, pages 180-187, 1990.
- [36]
- J. McLean. A general theory of composition for trace sets closed under selective interleaving functions. In IEEE Symp. on Research in Security and Privacy, pages 79-93, 1994.
- [37]
- A. Myers. JFlow: Practical mostly-static information flow control. In ACM Symp. on Principles of Programming Languages, 1999.
- [38]
- G. Necula and P. Lee. The design and implementation of a certifying compiler. ACM SIGPLAN Notices, 33(5):333-344, 1998.
- [39]
- T. Nipkow, G. Bauer, and P. Schultz. Flyspeck I: Tame graphs. In Automated Reasoning, pages 21-35. Springer, LNCS 4130, 2006.
- [40]
- T. Nipkow, L. Paulson, and M. Wenzel. Isabelle/HOL — A Proof Assistant for Higher-Order Logic. Springer, LNCS 2283, 2002.
- [41]
- OASIS. WS-security policy 1.2. http://docs.oasis-open.org/ws-sx/ws-securitypolicy, 2007.
- [42]
- D. Pichardie. Building certified static analysers by modular construction of well-founded lattices. In 1st Int. Conf. on Foundations of Informatics, Computing and Software, ENTCS vol. 212, pages 225-239, 2008.
- [43]
- F. Pottier and S. Conchon. Information flow inference for free. In ACM Int. Conf. on Functional Programming, pages 46-57, 2000.
- [44]
- A. Roscoe. CSP and determinism in security modelling. In IEEE Symp. on Security and Privacy, pages 114-127, 1995.
- [45]
- A. Sabelfeld. The impact of synchronisation on secure information flow in concurrent programs. In 4th Int. Andrei Ershov Memorial Conf. on Perspectives of System Informatics, pages 225-239. Springer, LNCS 2244, 2001.
- [46]
- A. Sabelfeld and D. Sands. Probabilistic noninterference for multi-threaded programs. In 13th IEEE Comp. Security Foundation Works., pages 200-215, 2000.
- [47]
- A. Sabelfeld and D. Sands. A PER model of secure information flow in sequential programs. Higher Order and Symbolic Computation, 14(1):59-91, 2001.
- [48]
- A. Sabelfeld and D. Sands. Dimensions and principles of declassification. In 18th IEEE Comp. Security Foundations Works., pages 255-269, 2005.
- [49]
- F. Schneider, G. Morrisett, and R. Harper. A language-based approach to security. In Informatics: 10 Years Back, 10 Years Ahead, pages 86-101. Springer, LNCS 2000, 2000.
- [50]
- G. Snelting, T. Robschink, and J. Krinke. Efficient path conditions in dependence graphs for software safety analysis. ACM Trans. Softw. Eng. Methodol., 15(4):410-457, 2006.
- [51]
- Symantec Corporation. Symantec global internet security threat report. http://www.symantec.com/content/de/de/about/downloads/PressCenter/ISTR_XIII.pdf, 2008.
- [52]
- D. Volpano and G. Smith. A type-based approach to program security. In TAPSOFT'97, pages 607-621. Springer, LNCS 1214, 1997.
- [53]
- D. Volpano and G. Smith. Probabilistic noninterference in a concurrent language. Journal of Comp. Security, 7(2/3):231-253, 1999.
- [54]
- D. Volpano, G. Smith, and C. Irvine. A sound type system for secure flow analysis. Journal of Comp. Security, 4(3):167-187, 1996.
- [55]
- D. Wasserrab and A. Lochbihler. Formalizing a framework for dynamic slicing of program dependence graphs in Isabelle/HOL. In 21st Int. Conf. of Theorem Proving in Higher Order Logics, pages 294-309. Springer, LNCS 5170, 2008.
- [56]
- R. Wilhelm et al. The worst-case execution-time problem – overview of methods and survey of tools. ACM Trans. on Embedded Computing Systems, 7(3):1-53, 2008.